「CV」 三维重建资源汇总
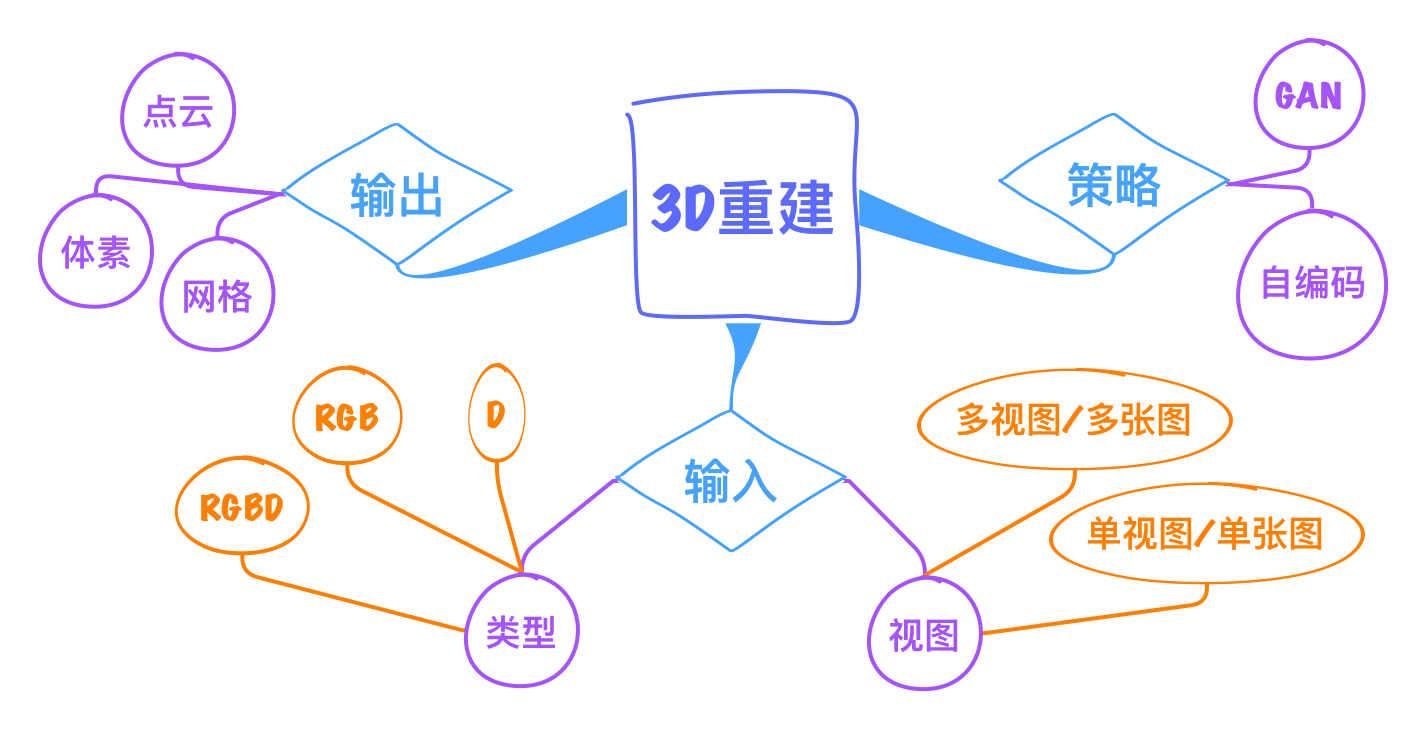 图1. 三维重建任务概览
图1. 三维重建任务概览
关键词:3D reconstruction · generative · 3D mesh
1 基础
1.1 体素 VS 点云
体素:volume pixel(voxel),与二维的像素一样,需存储所有三维像素点,没有物体的地方像素值为 0;像素具有规律性的排列,可以直接套用卷积神经网络;运算时需要庞大的内存与运算量;
点云:point cloud,是三维点的集合,只需记录物体所在的点的坐标;没有规律性的排列,因此无法套用卷积神经网络;高分辨率下,比较节省内存与运算量,也比较适合表示高分辨率的三维物体;
2 综述
- Image-based 3D Object Reconstruction: State-of-the-Art and Trends in the Deep Learning Era
2019-06-15 paper
3 理论
4 单视图重建
4.1 GAN
使用二维编码器、三维解码器(即 GAN 中的成器)和判别器;
-
Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling
NIPS 2016 2016-10-24 paper | project torch
3D GAN -
Transformation-Grounded Image Generation Network for Novel 3D View Synthesis
CVPR 2017 2017 paper | project | torch-official -
Weakly supervised 3D Reconstruction with Adversarial Constraint
27-05-31 Paper | theano | 解读 -
3D Shape Induction from 2D Views of Multiple Objects
CVPR 2017 2016-12-18 Paper | Python
弱监督三维重建 - Visual Object Networks: Image Generation with Disentangled 3D Representation
NIPS 2018, VON, 谷歌 Paper | Pytorch | Project
单视角·GAN + AE·WGAN-GP
单张图像生成三维图像:启发自经典的图形学,我们将三维图像生成分为形状、视角和纹理三个部分,并使用 GAN 进行学习;网络先学习到三维形状,然后转为 2.5D(即轮廓和深度图),再对深度图施加纹理,以生成逼真的图像;
文章使用独立的网络完成上述各操作,包括 $GAN_{shape}$(WGAN-GP),$GAN_{texture}$(PatchGAN + LS-GAN + AE-ResNet),$Estimate_{texture}$(AE-ResNet),$Estimate_{2.5D}$(AE-ResNet);
$GAN_{shape}$:2D 输入用的 Pix3D 数据集,3D 输入用的 ShapeNet 数据集;(均使用了椅子和车分类);使用 FID 评估 GAN 的效果;最终效果是挺好,只是从理论上看速度就够慢的;不过开源了这么多代码,也是挺实用;
-
GAL: Geometric Adversarial Loss for Single-View 3D-Object Reconstruction
ECCV 2018, 腾讯优图,香港中文 Paper
点云·GAN·3D卷积·点度量 -
Learning Single-View 3D Reconstruction with Limited Pose Supervision
ECCV 2018 Paper | Tensorflow
弱监督 - Global-to-Local Generative Model for 3D Shapes
SIGGRAPH 2018, 深圳大学 Paper | Tensorflow | Project
从三维物体的组件出发,生成同样结构的另外一种三维物体;使用基于体素的 GAN 对整体三维模型进行建模,得到多个局部结构,该网络有两个判别器,一个作用于整体,一个作用于局部,最后还有质量损失函数;之后使用条件自编码网络来重组局部结构得到三维模型;文章还提出了新的评价 GAN 模型的方法;摘要读起来很乱啊;
- Learning View Priors for Single-view 3D Reconstruction
CVPR 2019 Paper | Project 马上开源
$\bullet \bullet \bullet$
使用 GAN,并且融合了单视图重建和视角信息;
4.2 自编码
针对二维(输入)和三维(标签)分别训练出一个自编码器,得到的两个编码向量越接近越好;使用时,先用二维编码器得到特征向量,然后用三维解码器得到对应的三维数据(可以是体素,也可以是点云);
-
Category-Specific Object Reconstruction from a Single Image
2014-11-22 Paper
在 PASCAL VOC 2012 和 PASCAL 3D+ 数据集上进行实验,利用关键点和图像分割标签并结合视角估计进行三维重建;核心理论是基于 EM 最大化; - Mesh-based Autoencoders for Localized Deformation Component Analysis
2017-12-16 Paper
针对三维几何形状分析与合成问题中变形部位提取问题中,当变形较大时效果不好的情况,提出了使用稀疏正则化来帮助提取局部变形;总结分析跟没写一样;
-
Exploring Generative 3D Shapes Using Autoencoder Networks
2017 Paper
将非结构化的三角网格转化为具有拓扑的矩形网格;输入输出都是三维结构; -
Variational Autoencoders for Deforming 3D Mesh Models
CVPR 2018 2017-09-13 Paper | Matlab
$\bullet \bullet$什么是条件 VAE
使用 VAE 分析三维形状,可用于三维结构生成、三维结构插值和特征嵌入;具体的应用有姿态变换,手势变换和表情迁移;文中还提到了条件 VAE; -
DeformNet: Free-Form Deformation Network for 3D Shape Reconstruction from a Single Image
2017-08-11 Paper
$\bullet \bullet$怎么解决的推理问题
编码信息中融合了二维图像和三维图像的信息; - Using Locally Corresponding CAD Models for Dense 3D Reconstructions from a Single Image
CVPR 2017 Paper
利用二维图像及其关键点,重建三维模型;早期的模型都要么是基于一组 CAD 映射,要么是的各映射元素之间进行混合,都很难融合到 CNN 里,本文想了个两阶段的策略,把这些融合进去了;其中使用了图卷积;在合成数据集和真实数据集上表现都很好;
什么叫 dense 3D shape of an object感觉是三维重建的另一个分支了
-
Compact Model Representation for 3D Reconstruction
2017 Paper | Code -
Image2Mesh: A Learning Framework for Single Image 3D Reconstruction
2017 Paper | Code -
Learning free-form deformations for 3D object reconstruction
ACCV 2018 Paper | Tensorflow -
Lions and Tigers and Bears: Capturing Non-Rigid, 3D, Articulated Shape from Images
CVPR 2018 Paper - GRASS: Generative Recursive Autoencoders for Shape Structures
SIGGRAPH 2017 Paper | Matlab | Pytorch | Project
自编码·对称结构·图卷积·RNN
从物体的层次性和对称性入手提高生成效果:GRASS,
几何结构编码:将物体各部位的外接框编码成固定长度的向量;
循环自编码:使用 RNN 作为自编码网络,将每一个目标框编码成特征向量,同时生成起层次结构;然后使用相反的结构来恢复物体框;使用重建损失来指导训练;
学习局部结构:在自编码基础上,加入 GAN,来生成物体形状;GAN 根据物体的多个局部编码生成其三维结构;
几何合成:使用了复杂的组合模型来探索三维图像的几何结构问题,针对不同的部位单独生成其对应的三维模型,来提高生成效果;(论文很难读);
- Cross-modal Deep Variational Hand Pose Estimation
2018-03-30 Paper
手 3D 姿态估计·VAE
$\bullet \bullet$怎么论证的 VAE 效果比 GAN 好那段数学证明在干嘛
使用 VAE 从平面图估计出手的三维姿态;并为此,根据 AVE 的变分下界推导出目标函数;可是最后还是用的 KL 散度和 L2 啊文中的多模态指的是数据格式不同——RGB、二维、三位和深度图;
-
GRAINS: Generative Recursive Autoencoders for INdoor Scenes
2018-07-24 Paper
使用递归变分自编码网络进行三维室内场景生成; VAE 主要负责 2D 转 3D;RNN 在里边干啥了 - 3D Shape Reconstruction from a Single 2D Image via 2D-3D Self-Consistency
2018-11-29 paper摘要很烂,所用方法之字未提;
-
Learning single-image 3D reconstruction by generative modelling of shape, pose and shading
2019-01-19 Paper 弱监督三维重建; - Learning to Infer and Execute 3D Shape Programs
ICLR 2019 Paper | Pytorch | Project
问题:3D 图像的表示可以用体素,点云和网格;这些方式各有优劣,但是都无法表示物体的边缘和平面特性;
方案:本文用程序(事先定义好语言)来表示 3D 图像;并对物体的对称性和重复结构进行建模;
模型:模型包括一个程序生成器和一个程序执行器;生成器用于生成模型的表征程序,执行器用于执行生成的程序,且带有渲染功能;生成器包含两个 LSTM,并结合了 3D 卷积;
数据集:shapeNet,Pix3D和自建数据集;本文着眼于解析 3D 物体形状以在相关领域取得进一步的成果;模型整体上是自编码结构,只不过得到的「编码」不是数值,而是具有语法的文字;
文章是基于三维数据做的实验,作者认为该方法可以扩展到三维重建;
摘要没看懂; -
3D Organ Shape Reconstruction from Topogram Images
2019-03-29 Paper
基于 CT 的 3D 肝脏器官重建; -
Dense 3D Face Decoding over 2500FPS: Joint Texture & Shape Convolutional Mesh Decoders
2019-04-06 Paper
$\bullet \bullet$ -
Convolutional Mesh Regression for Single-Image Human Shape Reconstruction
2019 Paper
图卷积 - Photo-Geometric Autoencoding to Learn 3D Objects from Unlabelled Images
2019-06-04 paper
4.3 其他
-
Learning to Generate Chairs, Tables and Cars with Convolutional Networks
2014 Paper -
Weakly-supervised Disentangling with Recurrent Transformations for 3D View Synthesis
2015, NIPS Paper | Caffe -
Analysis and synthesis of 3D shape families via deep-learned generative models of surfaces
2015 Paper -
Structured Prediction of Unobserved Voxels From a Single Depth Image
CVPR 2016, Voxlets Paper | Python | Project
深度三维重建
根据单张深度图重建整个三维模型;
数据集:自建了数据集——tabletop 主要是包括遮挡情况,目前公开数据集很少包括这样的场景;NYU-Depth V2 数据集,我们把其中没有重建模型的数据,自己合成了对应的三维模型; -
3D-R2N2: 3D Recurrent Reconstruction Neural Network
ECCV 2016 Paper | Theano -
Perspective Transformer Nets: Learning Single-View 3D Object Reconstruction without 3D Supervision
NIPS 2016 Paper | Torch-Offical -
Learning a Predictable and Generative Vector Representation for Objects
ECCV 2016, TL-EmbeddingNet Paper | Caffe-Offical(for test) | Video -
Unsupervised Learning of 3D Structure from Images
NIPS 2016 Paper -
Generative and Discriminative Voxel Modeling with Convolutional Neural Networks
2016 Paper | Code -
Multi-view Supervision for Single-view Reconstruction via Differentiable Ray Consistency
CVPR 2017 Paper | Python-Offical -
Synthesizing 3D Shapes via Modeling Multi-View Depth Maps and Silhouettes with Deep Generative Networks
CVPR 2017 Paper | Torch-Lua -
Shape Completion using 3D-Encoder-Predictor CNNs and Shape Synthesis
CVPR 2017 Paper | Torch -
Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs
2017 Paper | Code -
Hierarchical Surface Prediction for 3D Object Reconstruction
2017 Paper -
OctNetFusion: Learning Depth Fusion from Data
2017 Paper | Code | Caffe -
A Point Set Generation Network for 3D Object Reconstruction from a Single Image
2017 Paper | Tensorflow -
Learning Representations and Generative Models for 3D Point Clouds
ICML 2018 Paper | Tensorflow-Offical -
Shape Generation using Spatially Partitioned Point Clouds
BMVC 2017 Paper -
PCPNET:Learning Local Shape Properties from Raw Point Clouds
2017 Paper | Torch -
Tag Disentangled Generative Adversarial Networks for Object Image Re-rendering
IJCAI 2017 优必选 Paper | Video -
3D Shape Reconstruction from Sketches via Multi-view Convolutional Networks
3DV 2017 Paper | C++-Offical | Project -
Interactive 3D Modeling with a Generative Adversarial Network
3DV 2017 Paper | Lua-py -
SurfNet: Generating 3D shape surfaces using deep residual networks
CVPR 2017 Paper | Matlab -
3D-PRNN: Generating Shape Primitives with Recurrent Neural Networks
ICCV 2017 Paper | Pytorch-lua -
Large-Scale 3D Shape Reconstruction and Segmentation from ShapeNet Core55
ICCV 2017 Paper -
Pix2vox: Sketch-Based 3D Exploration with Stacked Generative Adversarial Networks
2017 Tensorflow-PyQt -
3D Sketching using Multi-View Deep Volumetric Prediction
2017 Paper -
MarrNet: 3D Shape Reconstruction via 2.5D Sketches
NIPS 2017 Paper | Pytorch | Project -
Learning a Multi-View Stereo Machine
2017 NIPS, 伯克利 Paper | Tensorflow | Blog -
Scaling CNNs for High Resolution Volumetric Reconstruction from a Single Image
2017 Paper -
ComplementMe: Weakly-Supervised Component Suggestions for 3D Modeling
SIGGRAPH 2017 Paper | Tensorflow-Offical | Project -
[Learning to Reconstruct High-quality 3D Shapes with Cascaded Fully Convolutional Networks](http://openaccess.thecvf.com/content_ECCV_2018/papers/Yan-Pei_Cao_Learning_to_Reconstruct_ECCV_2018_paper.pdf)
ECCV 2018 2018 paper
3D FCN; -
Neural 3D Mesh Renderer
CVPR 2018 Paper | Chainer-Offical | Pytorch | Tensorflow-Chainer | Project -
Multi-view Consistency as Supervisory Signal for Learning Shape and Pose Prediction
CVPR 2018 Paper | Pytorch-Offical | Project -
Object-Centric Photometric Bundle Adjustment with Deep Shape Prior
2018 Paper -
Learning Efficient Point Cloud Generation for Dense 3D Object Reconstruction
AAAI 2018 Paper | Tensorflow-Offical | Project -
Pixel2Mesh: Generating 3D Mesh Models from Single RGB Images
2018, 复旦大学、普林斯顿大学、Intel Labs 和腾讯 AI Lab Paper | Tensorflow -
AtlasNet: A Papier-Mâché Approach to Learning 3D Surface Generation
2018 CVPR Paper | Pytorch-Offical | Project -
Deep Marching Cubes: Learning Explicit Surface Representations
CVPR 2018 Paper | Pytorch -
Im2Avatar: Colorful 3D Reconstruction from a Single Image
2018 Paper | Tensorflow-Offical | Project -
Learning Category-Specific Mesh Reconstruction from Image Collections
ECCV 2018, 伯克利 Paper | Pytorch-Offical | Project -
Layer-structured 3D Scene Inference via View Synthesis
ECCV 2018 Paper | Tensorflow | Project -
Sidekick Policy Learning for Active Visual Exploration
ECCV 2018 Paper | Pytorch | Project -
Im2Pano3D: Extrapolating 360° Structure and Semantics Beyond the Field of View
CVPR 2018 Paper | Pytorch-Matlab | Project -
CSGNet: Neural Shape Parser for Constructive Solid Geometry
CVPR 2018 Paper | Python-2D-Offical | Python-3D | Project -
Multi-View Silhouette and Depth Decomposition for High Resolution 3D Object Representation
NIPS 2018 Paper | Tensorflow -
Pixels, voxels, and views: A study of shape representations for single view 3D object shape prediction
CVPR 2018 Paper | Pytorch-Offical | Project -
Neural scene representation and rendering
2018, GQN Paper | Chainer | Tensorflow | Pytorch | Project | Dataset-GQN
速度相当慢; -
Im2Struct: Recovering 3D Shape Structure from a Single RGB Image
CVPR 2018 2018.04.16 Paper | Matlab-Offical
CNN·LSTM
根据二维图像重建三维图像的 CAD 模型(以长方体表示 3D 物体的各个组件); -
FoldingNet: Point Cloud Auto-encoder via Deep Grid Deformation
CVPR 2018 2017.12.19 Paper | Project
图
$\bullet \bullet$损失函数用的什么2D-3D框架
使用 3D 的自编码器进行点云重建,且框架可以用作 2D 转 3D; -
Pix3D: Dataset and Methods for Single-Image 3D Shape Modeling
CVPR 2018 2018.4.12 Paper | Tensorflow-Offical | Project
$\bullet \bullet$评估标准是什么常用的二维图像编码是什么
一个可用于三维重建的数据集,考虑到现有的数据集要么是只有三维模型,要么是二维和三维数据之间缺乏对应关系,或者就是数据量太小;我们提出了一个新的三维重建评估标准,还在这个数据集上对前沿算法上进行了测评; - 3D-RCNN: Instance-level 3D Object Reconstruction via Render-and-Compare
CVPR 2018 Paper | Author | Project
输入二维图像,检测到目标后,对目标进行三维重建,然后映射回原图;怎么做的重建最终的效果很像实例分割啊
-
Matryoshka Networks: Predicting 3D Geometry via Nested Shape Layers
CVPR 2018 2018.4.29 Paper Pytorch |
$\bullet \bullet$
针对三维重建问题,我们提出了一个高效的网络;核心思想是把三维重建问题当作是二维预测问题;我们先跑了个基准网络,直接根据 2D 图像预测 3D 体素;使用经过验证的基于像素的图片预测任务,效果有所提升;基于这个方法,我们提出了一个能够记忆形状的编码网络,可以递归地重建三维物体,达到高分辨率; -
ALIGNet: Partial-Shape Agnostic Alignment via Unsupervised Learning
SIGGRAPH 2018 Paper | Pytorch-Offical-lua | Project
无监督
ALIGNet:基于无监督学习的未知局部形状对齐:将2D 图像对齐到未知的三维形状,传统方法都是匹配特征点来对齐,此时当一部分形状缺失时就无法进行对齐;本文针对缺失的部分专门提供了一个损失函数; -
PointGrid: A Deep Network for 3D Shape Understanding
CVPR 2018 Paper | Tensorflow
3D 识别 - Learning to Reconstruct 3D Manhattan Wireframes from a Single Image
2019-05-17 paper
4.4 RGB-D
- 3DMatch: Learning Local Geometric Descriptors from RGB-D Reconstructions
CVPR 2017 Paper | Matlab-Offical | Project
5 多视图重建
5.1 GAN
- Learning 3D Shapes as Multi-Layered Height-maps using 2D Convolutional Networks
ECCV 2018 2018-07-23 Paper | Pytorch
CNN·3D 形状分类·ModelNet·DCGAN
5.2 自编码
5.3 其他
- Conditional Single-view Shape Generation for Multi-view Stereo Reconstruction
CVPR 2019 2019-04-14 paper | tensorflow-offical
多个视角单独重建的结果取交集;这就需要假设,未知视线下重建结果是多的,感觉不是很合理啊;
6 基于视角的重建
7 其他
- Occupancy Networks: Learning 3D Reconstruction in Function Space
CVPR 2019 2018-12-10 paper | pytorch-offical
附录
A 参考资料
[1]. 维基百科. 三维重建[EB/OL]. https://zh.wikipedia.org/wiki/%E4%B8%89%E7%BB%B4%E9%87%8D%E5%BB%BA. -/2019-03-28.
[2]. dragonlong. Trending in 3D Vision[EB/OL]. https://github.com/dragonlong/Trending-in-3D-Vision. -/2019-03-28.
[3]. timzhang642. 3D-Machine-Learning[EB/OL]. https://github.com/timzhang642/3D-Machine-Learning. -/2019-03-28.
[4]. poodar.chu. 点云感知 CVPR 2018 论文总结. https://zhuanlan.zhihu.com/p/41287237. 2018-08-04/2019-03-28
[5]. sophie. CVPR 2019 论文汇总[EB/OL]. http://bbs.cvmart.net/topics/302/cvpr#12. 2019-03/2019-07-12.
Comments