「论文解读」 Dual Encoding for Zero-Example Video Retrieval
论文发表时间:2018-09-17 CVPR 2019
作者: Jianfeng Dong, Xirong Li, Chaoxi Xu, Shouling Ji, Yuan He, Gang Yang, Xun Wang
单位: 浙江工商大学,浙江大学,阿里巴巴,中国人民大学数据工程与知识工程重点实验室,中国人民大学信息学院AI与媒体计算实验室
论文地址: https://arxiv.org/abs/1809.06181
官方代码: pytorch https://github.com/danieljf24/dual_encoding
1 概述
使用对偶网络进行零样本视频检索;直接映射到同一个特征空间,不依赖于概念;
2 方案
前导知识:深度学习基本知识,CNN,视频分类
2.1 模型结构
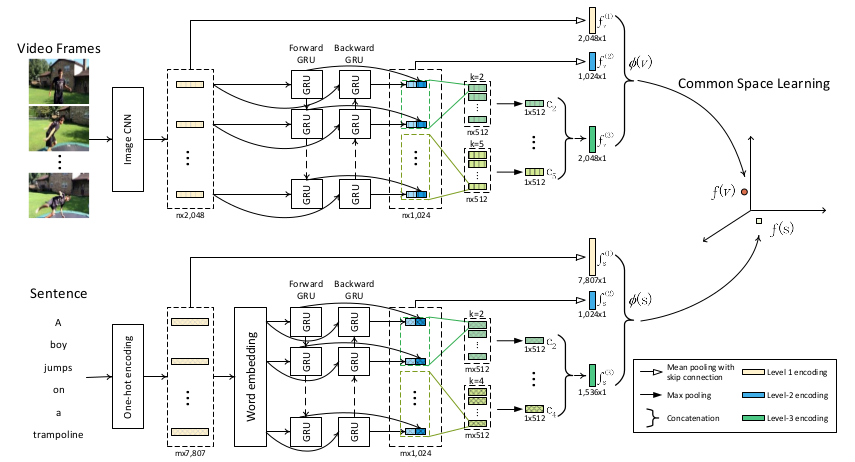
图1:网络结构
使用的模块有: CNN,BiGRU-CNN,FPN,VSE++
2.2 视频特征提取
- 第一层 $f_v^1$:
每 0.5s 组成一个片段,用 CNN 进行特征提取;最终得到一个 2048×n 维的视频特征序列 {$v_1, v_2, …, v_n$},对他们做平均池化,得到$f_v^1$; - 第二层——时序感知模块 $f_v^2$:
使用 BiGRU 提取视频时序特征,得到 1024×n 维特征 H = {$h_1, h_2, …, h_n$}; - 第三层——强判别性特征 $f_v^3$:
使用 1D 卷积+最大池化处理 H 得到 [$c_1, c_2, c_3, c_4, c_5$];
上述三个特征拼接起来得到视频特征: $\phi (v) = [f_v^1, f_v^2, f_v^3]$;
2.3 文本特征提取
视频特征提取网络稍作修改就可用于文本特征提取;
- 第一层 $f_s^1$:
给定句子 s 包含 m 个词汇,那么为每个单词生成一个 one-hot 特征向量 {$w_1, w_2, …, w_m$},向量长度为该数据集中词汇的个数;特征提取网络使用的是基于 3 百万数据的预训练模型;
其余两层同视频特征提取,得到文本特征: $\phi (s) = [f_s^1, f_s^2, f_s^3]$;
2.4 映射到同一个特征空间
使用 VSE++ 算法 得到 最终的特征 $f_v$ 和 $f_s$;也就是全连接层,额外加了个 BN,发现效果更好了;
3 损失函数
使用经典的带间隔的排序损失:
\(\begin{align}
L &= \max (0, \alpha + S_\theta(v, s^-) - S_\theta(v, s)) + \max (0, \alpha + S_\theta(v^-, s) - S_\theta(v, s)) \label{loss}\\
\end{align}\)
公式 $\eqref{loss}$ 中 $\alpha$ 是间隔,$s^-$ 和 $v^-$ 是文本和视频负样本;
4 实验
4.1 数据集
MSR-VTT, TRECVIR 2016&2017, MSCOCO;
4.2 实验结果
总之就是效果好,没啥分析;这部分可以不看;
4.2.1 精度
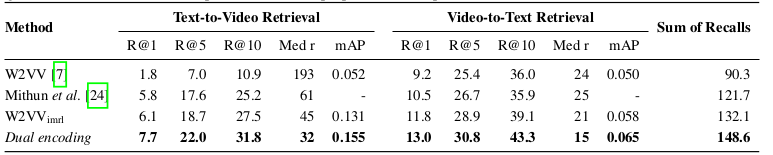
图2:MSR-VTT 实验结果
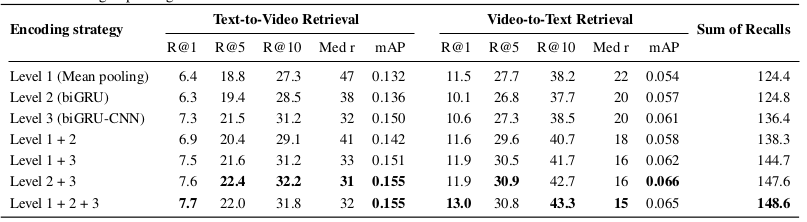
图3:MSR-VTT 上的消融实验
第三行和倒数第二行有什么区别吗
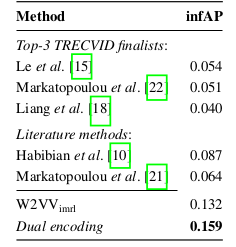
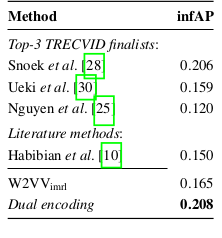
图4:TRECVIR 实验结果
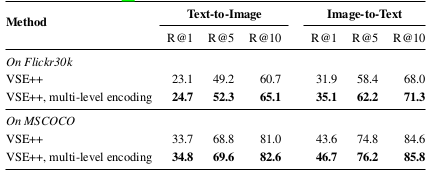
图5:MSCOCO 实验结果
4.2.2 速度
64G RAM,1080Ti 显卡,检索 335944 的视频库,速度是 140 ms 一次; 怎么测试的,批次多大
5 思考
1.本文并为解决「概念集合」难以确定的问题
文中说基于概念的方法的一个缺点是很难确定概念集合,那么本文的网络结构中,词向量 $f_s$ 的长度需要和词库中词汇个数相等,词库不正是概念集合吗?这么说来,文章并没有解决概念集合难以确定的问题;
由此可见,「零样本视频检索」中的零样本对应的其实是「视频零样本」,而不是「文本零样本」;对于文本来说,一直都是一个了「闭集」,只不过是集合大小的问题;
2.文本网络中第一层特征长度为什么要等于词汇个数
就是 onehot,为了标明当前输入的字符是什么;
3.如何理解零样本检索中的「零样本」
「零样本」指的是实际使用时,可以检索训练过程中未出现过的文本;例如:
| ID | 文本 | 视频 | 训练数据 |
|---|---|---|---|
| 1 | A girl eats lunch at the white table. | A | 是 |
| 2 | A policeman driving a black car. | B | 是 |
| 3 | A girl eats lunch at the black table. | C | 否 |
| 4 | A girl driving a black car. | D | 否 |
对于后两组数据,该文本虽然在训练时未出现过,但是模型也能够进行预测;这种情况就是「零样本」;
究其原因,有两点:
- 视频网络在训练阶段捕获到了「人的身份」和「颜色」特征;
- 文本网络中,RNN 具有组合能力,可以针对不同的输入序列,输出相应的特征;
一言以蔽之,只要检索中用了文本,就会用到 RNN,有了 RNN 就有了「零样本」特性;:flushed:
当然,如果你非要用 CNN 来处理文本,那自然就丢掉了零样本这一特性:expressionless:
4.「零样本」是由网络中的哪一部分实现的
是由文本网络中的 RNN 模块(BiGRU)实现的;
该模块输入的是一个一个单词,输入不同的单词+不同的序列信息,最终得到的特征不同;
5.本文的检索功能能否用视频分类实现
「视频分类」使用的是 CNN,最终是给视频打标签;如果用视频分类来做这个任务,那么输入的文本会被当作是一个整体作为标签出现;
「零样本视频检索」因为对输入的文本使用了 RNN,使得其可以处理不同的文本序列;
所以视频分类最终效果与零样本检索不同;
其实前者就是「闭集检索」的实现;而后者是「开集检索」的一种实现;
本文设计的网络严格来说是半开集,因为虽然支持未曾见过的文本序列,但是组成改序列的单词,必须是要训练集中出现过的;
6.网络训练时正负样本比例是多少
公式 $\eqref{loss}$ 中出现了一组正样本,两组负样本,显然,正负样本是 1:2;
7.视频特征提取网络中的 RNN 有什么作用,是否也对「零样本」有贡献
:ghost:
8.不同层次的特征为什么要堆叠,原理是什么
:ghost:
6 总结
本文的方法简单高效,端到端; 什么是端到端
- 文章的整体结构确实新,但只是对现有结构的堆叠,从而增加了特征提取网络的复杂度,结构上并没有太新的地方;
- 针对模型效果好的问题,文章也并未进行深入地探讨和论证;
- 对于多模态映射到同一特征空间的问题,也只是一个概念上的说法,与之前其他方法并无本质区别,只是说法不同;
- 文章的总结写的也是毫无深意;
附录
A 术语
1. 零样本视频检索
视频检索的搜索条件可以是视频也可以是文本;本文讨论的是「零样本视频检索」,也就是用文字检索视频;
此处零样本指的是待检索的文本序列在训练集中未出现过;
2. 基于概念的方法
对于不同模态的数据相似度计算,会事先学习到一个模态到另一个模态所有可能的情况,这种映射结果,我们称之为「概念空间」;然后在计算相似度时,將两个模态的原数据统一映射到到概念空间,再计算其距离;1
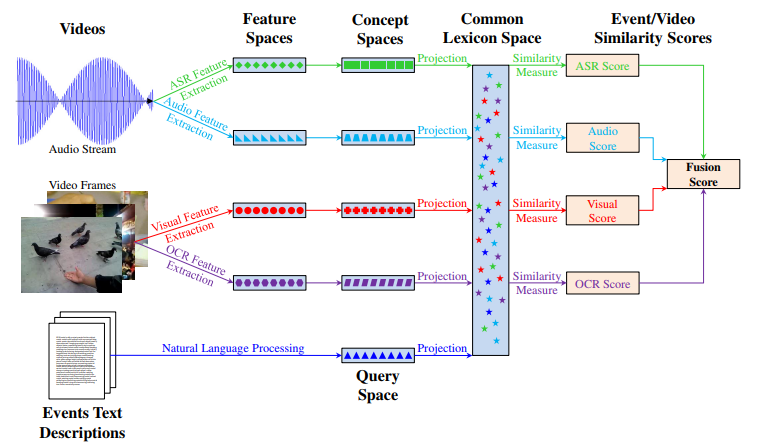
图6:基于概念的视频检索
3. 联合嵌入的方法
分别提取两个模态的特征,最后映射到统一的空间进行相似度度量;2
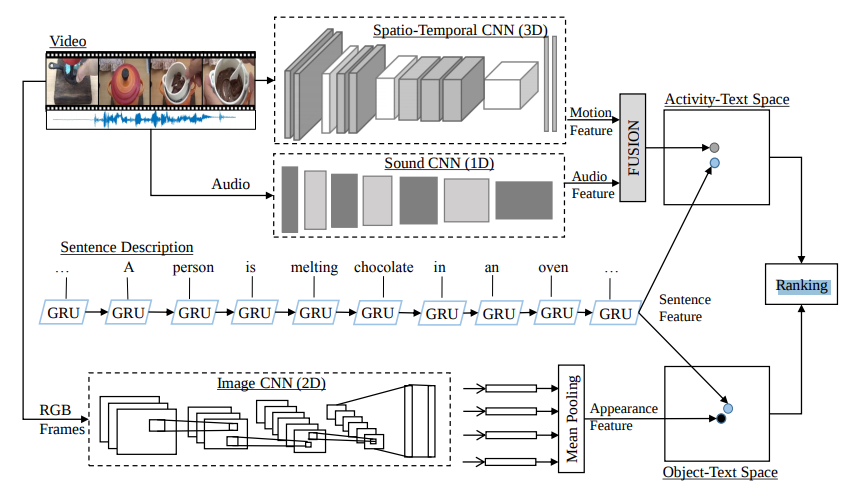
图7:基于联合嵌入的视频检索
4. 闭集 & 开集
这两个概念是在验证、检索任务中会用到的;是针对开发过程,和应用过程来说:
| 概念 | 开集 | 闭集 |
|---|---|---|
| 概念 | 指的是应用过程中(生产环境下)样本的标签未在开发过程中(训练集中)出现过 | 是应用过程中样本的标签需局限在开发过程时出现过的 |
| 优点 | 新类型的样本出现时无需更新模型 | 算法精度高; 开发过程相对简单; |
| 缺点 | 因追求较好的模型泛化能力而引起的开发过程困难; | 无法适应新数据,一旦需要支持新类型,必须更新算法模型,维护成本高 |
5. CNN
使用预训练的 ImageNet 分类模型;
6. BiGRU-CNN
GRU 类似于 LSTM,但是参数量更少,而且需要的训练数据也更少;双向指的是既能获取过去时序的特征,也能获取未来时序的特征;CNN 指的是在 BiGRU 之后接一个 CNN;
7. FPN
取不同层次的特征拼接在一起;在图像分类、检测领域有着广泛应用;几乎可应用于所有领域;
8. VSE++
将跨模态特征映射到同一特征空间;
B 参考文献
-
S. Wu, S. Bondugula, F. Luisier, X. Zhuang, and P. Natarajan. Zero-shot event detection using multi-modal fusion of weakly supervised concepts. In CVPR, 2014. ↩
-
N. C. Mithun, J. Li, F. Metze, and A. K. Roy-Chowdhury. Learning joint embedding with multimodal cues for cross-modal video-text retrieval. In ICMR, 2018. ↩
Comments