「论文解读」 Where And When to Look? Spatio Temporal Attention for Action Recognition in Videos
ICLR 2019
论文发表时间:2018-10-01
作者:Lili Meng, Bo Zhao, Bo Chang(不列颠哥伦比亚大学), Gao Huang(康奈尔大学)
论文地址:https://arxiv.org/abs/1810.04511

1 概述
第一句:在时间和空间同时使用注意力机制;注意力方法在视频分类中的普及;
第二句:使用时间-空间注意力机制和 RNN 助力视频分类;
第三句:弱监督视频定位;
2 基本流程
前导知识:CNN,深度学习基本知识,注意力,掩码
2.1 模型结构
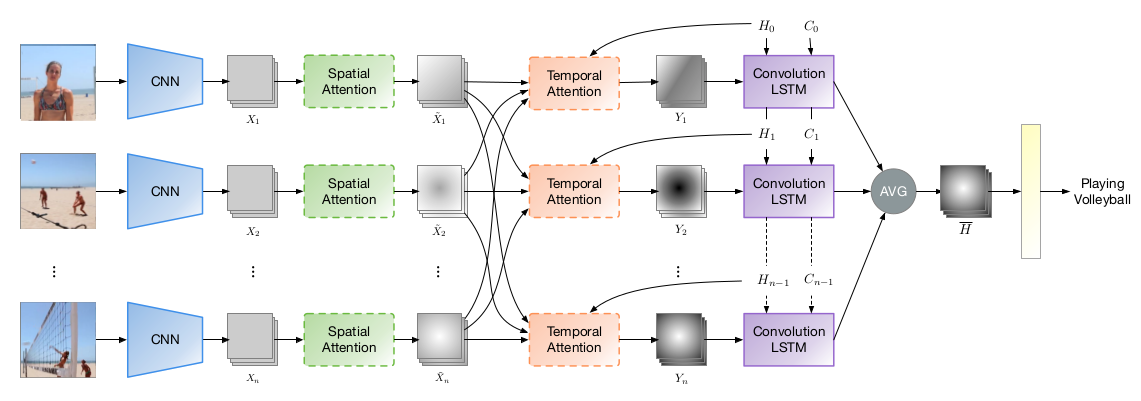
图1:模型结构
$H_t$ 代表 $t$ 时刻的状态信息;$X_i$ 表示第 $i$ 帧图像的特征图,$\hat X_i$ 表示第 $i$ 帧图像经过掩码后的结果;
论文目的是验证时空注意力在视频分类中的应用,所以骨干网络使用的是 resnet-50,而没有用 resnet-101,DenseNet,SENet 等性能更好的网络;在 ImageNet 与训练模型基础上进行训练;
时间 $t$ 的视频特征图:
\(\begin{align}
Y_t &= \frac{1}{n} \sum_{i=1}^{n}w_{ti} \hat X_i \label{yt}\\
\end{align}\)
$n$ 表示视频的帧数;某时刻的视频特征图为该时刻以前所有视频特征的均值;
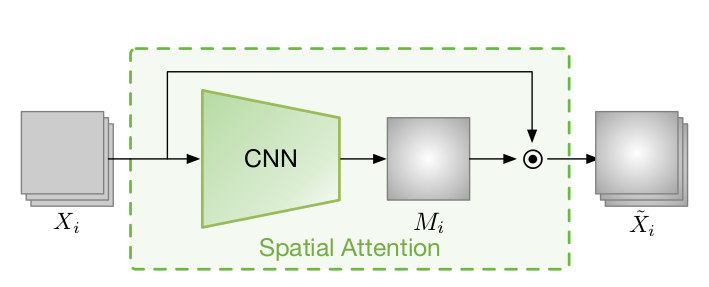
图2:空间注意力
空间注意力结果:
\(\begin{align}
\hat X_i &= X_i \cdot M_i \label{x_i}\\
\end{align}\)
其中,$M_i$ 为图像掩码,$X_i$ 是特征图;
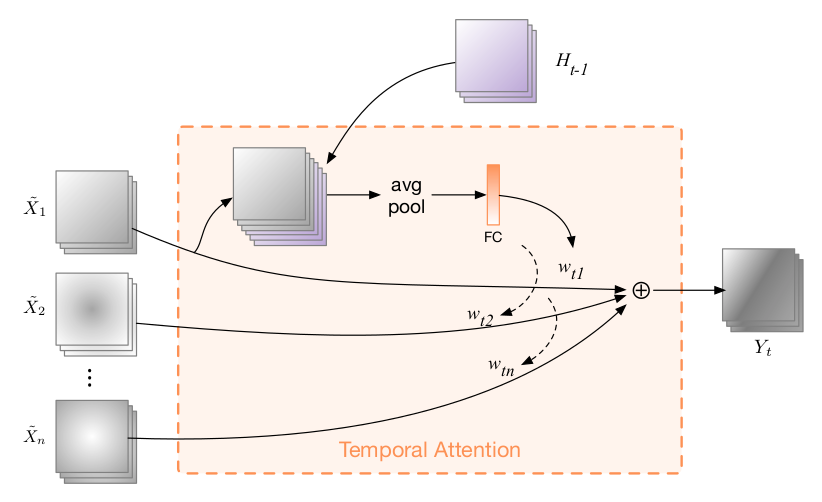
图3:时间注意力
时间注意力 $w_{ti}$:
\(\begin{align}
\phi &= \phi (H_{t-1}) + \phi_X(\hat X_i) \label{phi}\\
e_{ti} &= \phi (H_{t-1}, \hat X_i) \label{e_ti}\\
w_{ti} &= \frac{\exp(e_{ti})}{\sum_{i=1}^{n} \exp(e_{ti})} \label{w_ti}\\
\end{align}\)
3 损失函数
\(\begin{align} L &= L_{CE} + \lambda_{TV} L_{TV} + \lambda_{contrast} L_{contrast} + \lambda_{unimodal} L_{unimodal} \label{loss}\\ \end{align}\)
$L_{CE}$ 是分类任务的交叉熵损失;$L_{TV}$ 是在生成 mask,$L_{contrast}$ 是在增强 mask;$L_{unimodal}$ 提取的是时序注意力;
\(\begin{align} L_{TV} &= \sum_{i=1}^n \left( \sum_{j,k} \vert M_{i}^{j+1,k} - M_{i}^{j,k} \vert + \sum_{j,k} \vert M_{i}^{j,k+1} - M_{i}^{j,k}\vert \right) \label{loss_tv}\\ \end{align}\) 空间注意力损失:公式 $\eqref{loss_tv}$ 中使用 L1 距离在横纵两个方向捕获差异;$M_i$ 代表第 i 帧图像; $M_i^{j,k}$ 代表图像中 $j$ 行 $k$ 列的像素;
\(\begin{align} L_{contrast} &= \sum_{i=1}^n \left( -\frac{1}{2} M_i \cdot B_i + \frac{1}{2} M_i \cdot (1-B_i) \right) \label{loss_contrast}\\ \end{align}\) 空间注意力损失——增强:公式 $\eqref{loss_contrast}$ 中 \(B_i = I\{ M_i > 0.5 \}\) 是二值化之后的掩码图,也就是前景掩码;为了使前背景具有更大的区分度,便使掩码的前背景成对抗性;
\(\begin{align}
L_{unimodal} &= \sum_{t=1}^T \sum_{i=2}^{n-1} \max\{0, w_{t,i-1}w_{t,i+1} - w_{t,i}^2 \} \label{loss_unimodal}\\
\end{align}\)
时序注意力损失:公式 $\eqref{loss_unimodal}$ 中 $T$ 是 LSTM 中的时序长度;$n$ 是帧数;
假设时序显著性呈单峰模式,即 $a_{i-1} < a_i, a_i > a_{i+1}$, 便可得到公式 $\eqref{loss_unimodal}$;
4 实验
4.1 数据集
4.2 实验结果
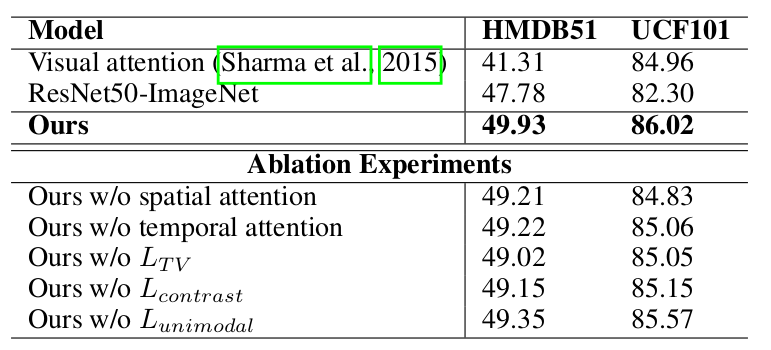
图4:与其他注意力模型对比结果
resnet50 比 GoogleNet 在视频分类中效果更好;
时空注意力机制有效提高了视频分类的准确度;
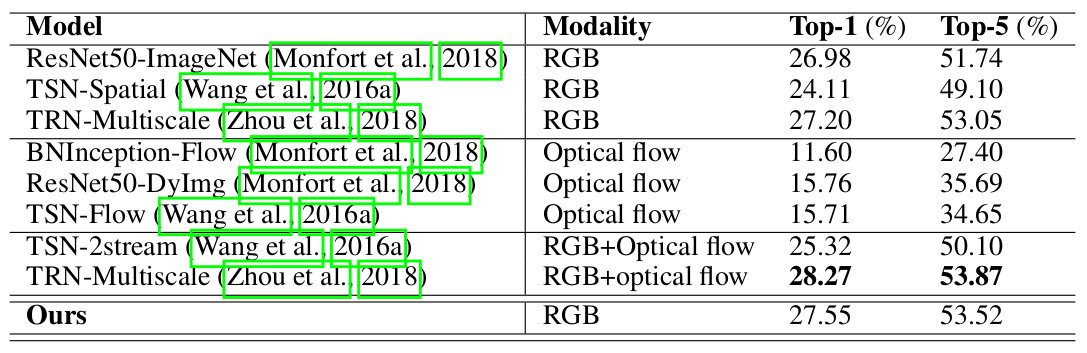
图5:与其他模型对比结果


图6:视频定位结果
注意力机制确实能够有效捕获时序权重;
5 思考
1.空间掩码对抗部分为什么假设前景越大越好
公式 $\eqref{loss_contrast}$ 中最终对 mask 做了什么求和?是在让前景区域更大吗?
2.为什么空间注意力要用 L1 损失,其他距离度量方式是否可以
3.空间注意力除了横纵方向的差异信息,其他邻域信息是否要注意
4.Loss 函数组合
深度学习中当网络更新受多个因素影响时,会将各影响因素求和,来指导网络更新;
5.关于空间注意力的 loss 函数的设计,没有更多的阐述
6.空间注意力提取时为什么使用 3 层卷积层,其他层数效果怎么样,其他结构会怎么样
7.公式 $\eqref{loss_unimodal}$ 中为什么要取 $max$
取了 $max$ 之后,岂不是只能训练到所有帧都均衡的状态,不会出现单峰吗?
6 总结
使用 LSTM + 时空注意力机制来提高视频分类效果,取得了进一步的成果;并且可以用来做视频定位,而且是弱监督的方法;
Comments