「论文解读」 Video Action Recognition Via Neural Architecture Searching
视频动作识别:在工业和学术界都是热点,因为这对于行为分析和情感计算等应用的基础;虽然目前该领域的数据集和神经网络都有着很大进步,但是这需要耗费大量的时间和专家;
视频任务对于时间和空间的需求决定了网络结构复杂和较高的计算代价;
神经网络自动搜索:Neural Architecture Search(NAS),是通过机器自动生成神经网络,通常效果都比人工设计的好;他在分类和分割等领域都有着很好的应用;
论文发表时间:2019-07-10 ICIP 2019
作者:Wei Peng, Xiaopeng Hong, Guoying Zhao
单位:奥卢大学,西安交大
论文地址:https://arxiv.org/abs/1907.04632
1 概述
使用基于伪 3D 操作的 AutoML 搜索出新的视频特征提取网络;
2 方案
前导知识:CNN,深度学习基本知识,视频分类
之前,神经网络搜索的输入都是低维数据(图像,文本),还没有高维数据(视频)相关的研究;
- 视频处理框架用的 TSN;
通过采样来降低大量的计算量; - 核心模块来自神经网络搜索;
使用伪 3D 卷积来降低计算量;
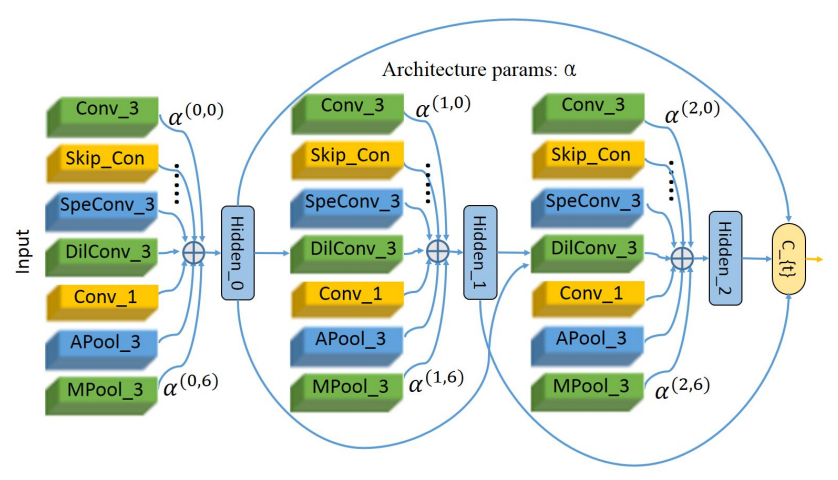
图1:网络结构
3 损失函数
SoftMax 分类;
迷人的是作者在训练集和验证集上同时训练,那还分什么验证集
4 实验
4.1 数据集
UCF-101;
4.2 实验结果
输入 3×(4×2)×112×112;
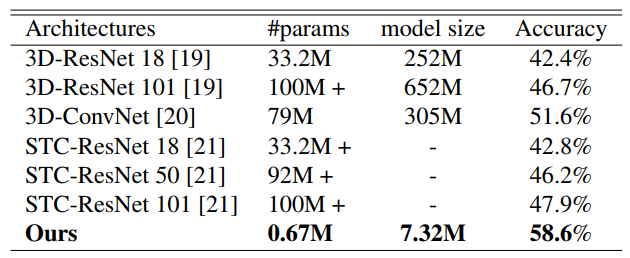
图2:UCF-101 上实验结果
5 思考
1.如何证明 module 内部的 1D 卷积就是在提取时序特征
在 stnet 中,1d 卷积在作用的时候,明显地将时间维度与通道维度交换,以此来保证该卷积的作用点是时序;可是本篇文章中所有操作都是同样的输入,那么如何区分了空间和时序;
如果不能证明此处某个特定的操作作用到了空间或时间,那么就不应该有伪 3D 这个概念;
所以,此处认为「伪 3D」这个概念无法自圆其说;
6 总结
6.1 结论
- 首次在视频任务中使用 AutoML;
- 使用了伪 3D 算子优化了 AutoML 搜索空间;
- 没有预训练的情况下,效果最佳,且参数是其他网络的 1%;
6.2 反思
在看到文章的摘要和引言时,还是挺激动的,因为视频任务本就繁琐,此时引入 AutoML 本身就非常亮眼,更何况文章还提到对 AutoML 进行了优化,使得耗时耗资源的 AutoML 变得轻量;然鹅:
- 引入的 AutoML 并没有解决视频任务的痛点
- 没有解决时序特征提取不佳;
虽然,之前不少网络都针对时序问题做了诸多工作,但是其泛化能力及工程可信度并不高;本文也只是使用 AutoML 找到了类似的新型网络结构,并无质地提升; - 没有解决视频输入数据量较大的问题;
此处直接使用了 TSN 的数据处理框架,并无新意;且均匀采样策略在视频任务中是否合适仍待讨论;
- 没有解决时序特征提取不佳;
- 关于 AutoML 的理论几乎没有;
- 没有说明为什么在视频任务中可用,或者有什么特点;
文中只是粗暴地引入了伪 3D 的概念,且最终也没能在网络结构上呈现出来;关于视频任务中的 AutoML 几乎没有探讨,更像是从图像问题直接迁移过来的; - 关于搜索空间压缩问题也没有论述;
因为文章只是事先设定好了一些结构,以此简化了搜索任务;关于为什么要使用这些结构,并没有说明;而且也不是用伪 3D 优化了搜索空间,用的是特定的结构;整体更像是半自动 AutoML,而不是优化了搜索空间的 AutoML;
- 没有说明为什么在视频任务中可用,或者有什么特点;
- 不过网络确实很轻巧;
但是如果要依赖于大量数据的预训练,那么其实使用起来也一般,倒不如来个知识蒸馏; - 文章的中心似乎也是在 AutoML 训练的策略上;
涉及到二阶可微,Hessian 矩阵等;
文章有一定的意义,但是感觉扯到视频上,就是在搞噱头;
附录
A 概念
1. 搜索网络相关符号

图3:网络中符号的意思
2. 伪 3D 卷积
即 (2+1)D 卷积,2D 卷积提取空间特征,1D 卷积提取时序特征;
B 术语
| 英文 | 中文 | 英文 | 中文 |
|---|---|---|---|
| directed acyclic graph | 有向无环图 | behaviour analysis | 行文分析 |
| affective computing | 情感计算 |
Comments