「论文解读」 StNet: Local and Global Spatial-Temporal Modeling for Action Recognition
AAAI 2019
论文发表时间:2018-11-05
作者:何栋梁,Zhichao Zhou,Chuang Gan,Fu Li,Xiao Liu,Yandong Li,Limin Wang,Shilei Wen
机构:百度,MIT-IBM Watson AI Lab,University of Central Florida,南京大学
论文地址:https://arxiv.org/abs/1811.01549
代码:Pytorch https://github.com/hyperfraise/Pytorch-StNet
- StNet 怎么提取视频特征的
- Temporal Xception Block 是什么
- Temporal Modeling Block 是什么
- 怎么提取时序特征的
1 概述
第一句:使用卷积网络(2D 和 3D 卷积)提取视频特征; 第二句:针对视频特征提取提出了 TXB 来获取时域特征;
2 方案
前导知识:CNN,深度学习基本知识
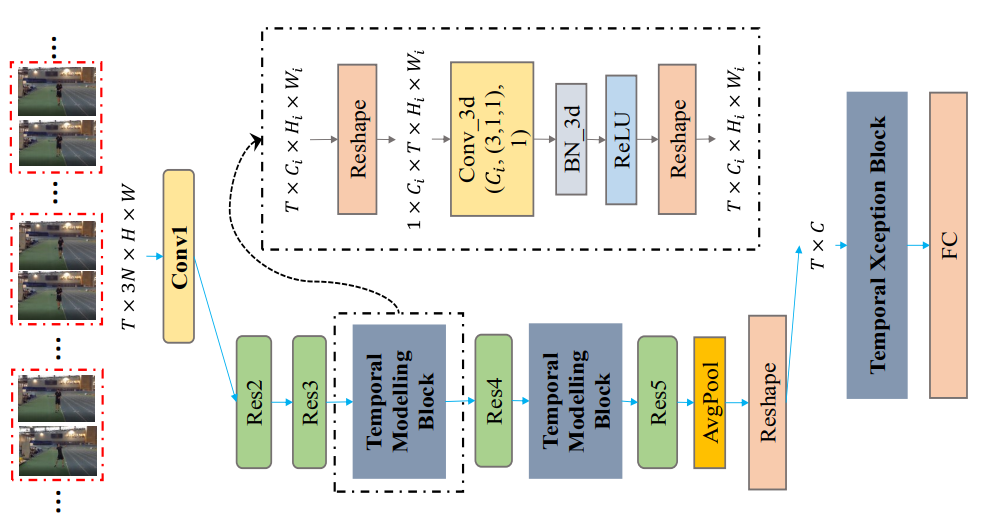
图1:StNet 示意图(基于 ResNet)
2.1 Super Image
提取局部时空特征;
2.2 Temporal Modeling Block
提取全局时空特征;使用 3D 卷积——Conv(3, 1, 1);
2.3 Temporal Sception Block
3 损失函数
\(\begin{align} \label{loss}\\ \end{align}\)
4 实验
4.1 数据集
4.2 实验结果
5 思考
1 StNet 怎么提取视频特征的
局部信息用二维卷积提取;网络层中加入 TMB 进行时序特征提取;
2 StNet 的输入是什么
$T \times 3N \times H \times W$
3 N 和 T 对模型效果有什么影响
4 Temporal Modeling Block 和 Temporal Xception Block 是什么,有什么区别
5 为什么 Temporal Modeling Block 中 3D 卷积核要用 1×1
6 网络怎么提取时序特征的
7 为什么要用 2D 卷积处理多帧图像,效果和 3D 卷积结果有什么不同
6 总结
对于视频特征提取,局部信息用二维卷积提取;然后在这些特征上应用时间 Xception 块,提取全局特征;模型小,效果好;
Comments