「论文解读」 Action Recognition Using Visual Attention
ICLR 2016 论文发表时间:2015-11-12
作者:Shikhar Sharma, Ryan Kiros & Ruslan Salakhutdinov
单位:Department of Computer Science, University of Toronto
论文地址:https://arxiv.org/abs/1511.04119
项目主页: http://shikharsharma.com/projects/action-recognition-attention/
官方代码:Theano https://github.com/kracwarlock/action-recognition-visual-attention


图1:注意力效果图
1 概述
首次使用 LSTM + CNN 模式 + attention 机制处理动作识别任务;
深度学习兴起之后,注意力机制被用于图像描述、机器翻译、游戏、跟踪和图像识别等领域;而且经常和 LSTM 等网络一起使用,效果良好;
贡献:研究了注意力机制在视频任务中的作用;
2 方案
前导知识:CNN,深度学习基本知识,注意力
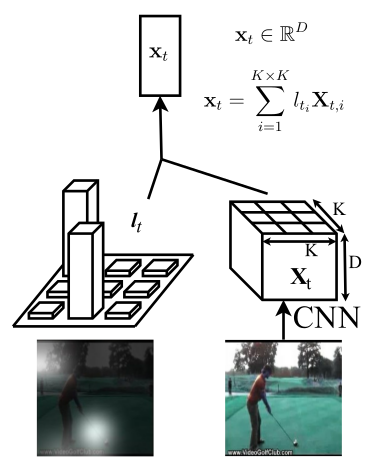
图2:空间软注意力机制
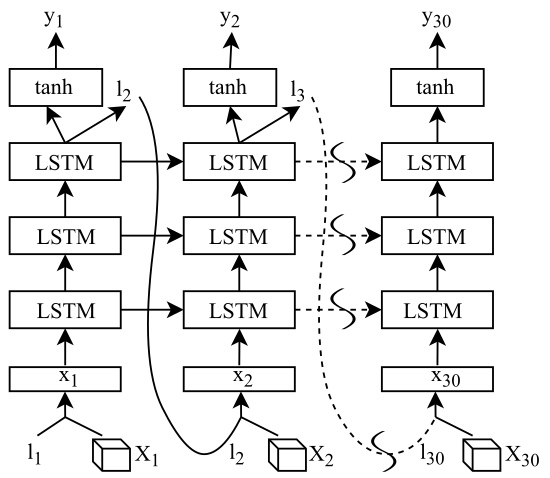
图3:网络结构
$X_t$ 是视频的第 $t$ 帧,尺寸为 $K\times K\times C$,$l_t$ 是第 $t$ 帧的注意力图,为 $K\times K$ 的向量,注意力图与卷积特征图逐点相乘得到 $x_t$;
CNN 使用的是 GoogLeNet,分辨率为 224x224,共 30 帧,LSTM 为 3 层,每一层的隐藏神经元为 512 个,在非循环层使用 dropout;
3 损失函数
\(\begin{align}
L &= -\sum_{t=1}^{T} \sum_{i=1}^{C} y_{t;i} \log \hat y_{t;i} + \lambda \sum_{i=1}^{K^2} \left( 1- \sum_{t=1}^{T} l_{t;i} \right)^2 + \gamma \sum_i \sum_j \theta_{i;j}^{2} \label{loss}\\
\end{align}\)
公式 $\eqref{loss}$ 中第一项为交叉熵损失,第二项为注意力损失,最后一项是权重衰减; 感觉不应该放在这
$C$ 为分类类别,$T$ 为时序;其中注意力损失会被限制在 0-1;$\lambda$ 为注意力惩罚因子;
4 实验
4.1 数据集
UCF-11,HMDB-51,Hollywood2
4.2 实验结果

图4:与其他模型的对比实验结果
1.引入注意力机制是否更有优势
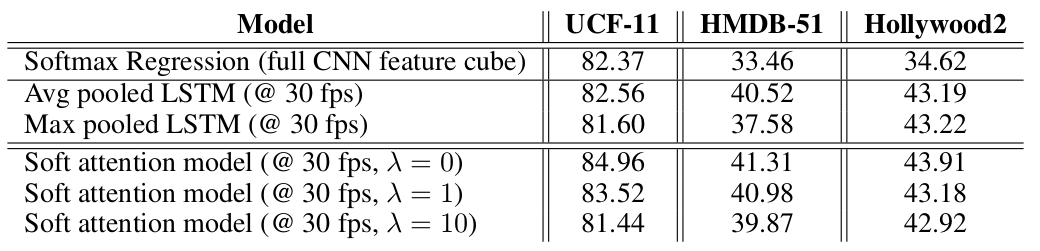
图5:与其他 baseline 的对比实验结果
与最大池化和平均池化相比,注意力机制效果更好;
2.损失项系数 λ 对注意力机制的影响
λ 为 0 时,只关注图像中的一小部分;λ 为 10 时,几乎关注了整幅图像;所以随着 λ 增大,注意力关注区域逐渐变大;
3.模型一般会关注视频帧中的哪些区域呢
一般情况下关注的是运动部位;但是如果遇到远景,会逐渐往背景部分扩展,直到能够正确分类为止;
4.输入的帧率会对聚焦的区域产生影响吗
注意力相应结果与输入帧率无关;
5.引入注意力机制模型的缺点
训练过程不稳定,注意力可能关注到无关的区域;
注意力对于分类结果存在决定性作用,当注意力不准确时,分类结果必然会出错;
5 思考
1.注意力向量从哪来
网络(LSTM)的最后一层特征图,后接全连接层和 $softmax$,得到的向量就是注意力向量;
2.注意力损失为什么要被限制在 0-1,怎么做到的
3.损失函数事实上考虑了时间和空间注意力,但为什么效果不好
6 总结
与没有使用注意力的 baseline 方法相比,我们的方法效果更好;
Comments