「论文解读」 A Joint Sequence Fusion Model for Video Question Answering and Retrieval
论文发表时间:2018-08-07 ECCV 2018
论文地址: https://arxiv.org/abs/1808.02559
官方代码: tensorflow https://github.com/yj-yu/lsmdc
- 研究的问题:视频问答/文本-视频检索
- 难点:子序列匹配;
- 现有的方法:
将跨模态特征表示成单个向量进行匹配,只能进行整体匹配,无法匹配到子序列;
1 概述
针对两种模态的序列数据,提出了可以度量子序列的方法;
2 方案
前导知识:深度学习基本知识,CNN,RNN, 视频检索, 视频问答
2.1 模型结构
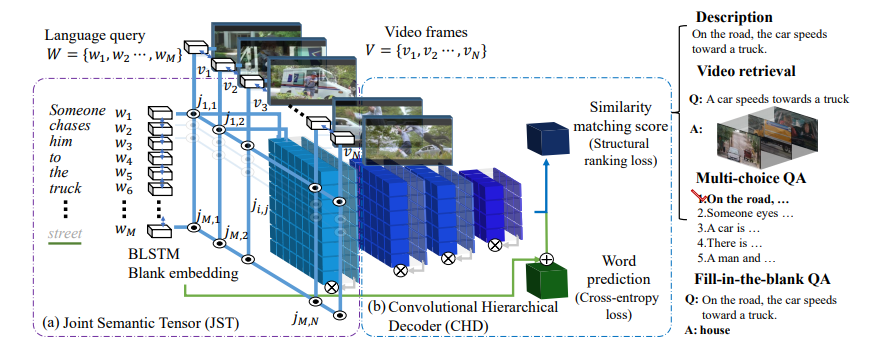
图1:网络结构
2.2 特征表示
Joint Semantic Tensor Fusion(JSFusion):针对各模态提取 3D 特征;然后进行融合;使用了软注意力机制;
视频:同时提取了图像和音频特征;每帧图像用 ResNet 的 pooling5 输出作为特征,最多 40 帧;音频用 VGGish 提取特征;
使用的模块有: ResNet-152,PCA,VGGish;
文本:从 LSMDC 数据集上制作一个字典,16824×300 维表示单词特征,一个句子最多 40 个单词;
JST:两个模态的特征进行映射,无法映射的情况直接剔除;
- 编码:输入成对的序列,文本用双向 LSTM 处理,图像用 CNN 处理;
- 嵌入:使用了注意力;
2.3 特征(分层)解码
Convolutional Hierarchical Decoder(CHD):对特征进行分层对齐;使用了 conv-gate 实现的时序注意力;
3 损失函数
使用经典的带间隔的排序损失:
\(\begin{align}
L &= \sum_k \sum_{l=1}^L \max (0, S_{k, l} - S_{k, l^*}) + \Delta) + \lambda |\theta|^2 \label{loss}\\
\end{align}\)
公式 $\eqref{loss}$ 中 $l^*$ 是正样本, k 是视频;
4 实验
4.1 数据集
M:MSR-VT, L:LSMDC——JSFusion;
4.2 实验结果
4.2.1 精度
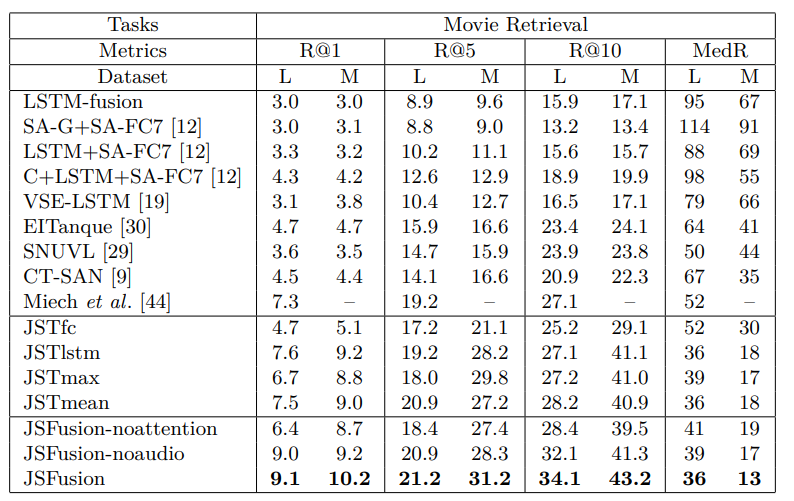
图2:检索任务效果
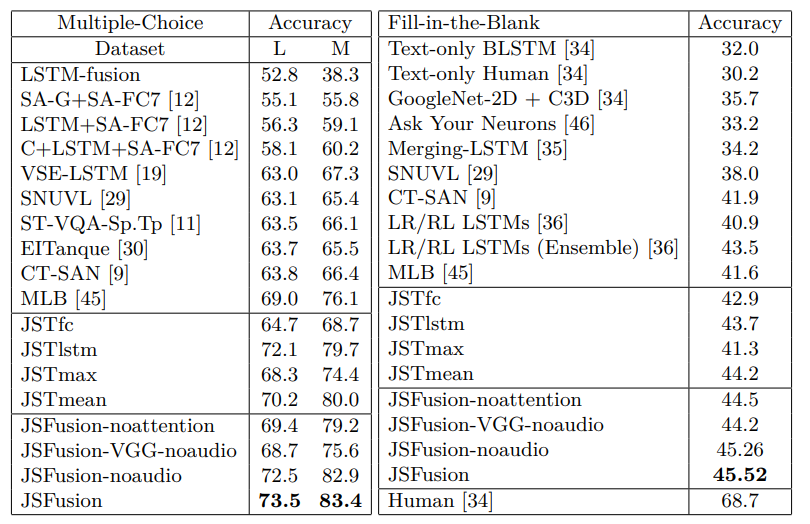
图3:VQA 准确度
4.2.2 速度
5 思考
6 总结
任何多模态序列任务中都可以用这个模型;
Comments